0. 更新日志
- 2025-02-11: 搭建本地大模型服务
- 2025-02-12: 更新 Continue 推荐配置
1. 本地大模型服务
AI 的时代已经到来, 作为程序员应积极响技术变化, 学会使用 AI 工具并利用其解决问题. 本地介绍如何在本地搭建大模型服务, 之所以搭建本地模型有两个原因:
- 更好的熟悉和学习大模型
- 无网状态下继续使用 AI 工具
- 数据安全
搭建本地模型使用的开源工具有:
- ollama: 获取和运行模型(多平台)
- vllm: 适用于 LLM 的高吞吐量和内存高效推理和服务引擎
- open-webui: 提供友好的用户界面来使用 ollama 和 OpenAI API 标准兼容的其他模型服务
以上三个工具中前两个都是获取运行模型的, 之所以本文介绍两个是因为 ollama 的模型仓库模型数量有限, 如果想尝试其他的模型则可以使用 vllm, 如果只是轻度使用那么 ollama 一个服务引擎则足够了; open-webui 其实也非必要, 因为 ollama 可以在终端中运行模型也可以进行对话, 但是终端对话简单, open-webui 可以实现联网搜索/切换模型/文件上传等高级功能, 用户体验更好.
Note
- 本文的搭建方法需要配置较好的计算机, 本人使用的是: MacBook Pro, Apple M2 Pro 芯片, 16GB 内存
- 本文搭建方法不限制计算平台, Linux/Windows 均可以, 只需要按照相关工具对应平台的安装方式安装即可
2. 安装工具
2.1 ollama
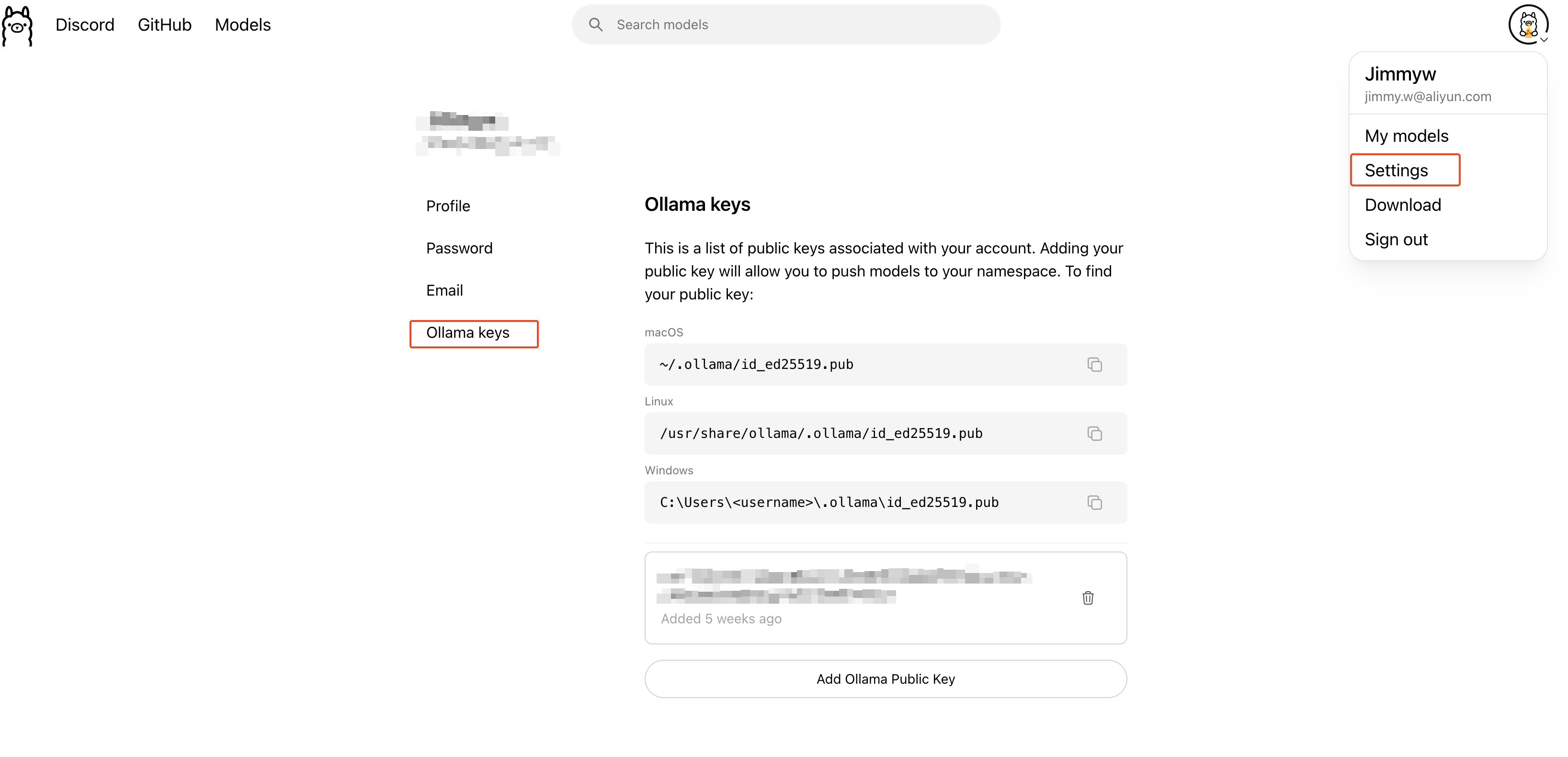
2.2 vllm
Note
vllm 非必要安装, 只有在 ollama 模型仓库找不到模型是 vllm 则是一个必选步骤, 所以您可以先浏览 ollama 模型仓库, 查看 ollama 提供的模型是否已经满足需求.
安装 vllm 稍微复杂一下, 如果是 linux 直接使用 pip 安装即可, 但是 vllm 当前没有针对 Apple silicon 的 wheels 所以需要从源码安装:
1 | # 拉取 vllm 代码 |
vllm 是从 huggingface 拉取模型的并提供 OpenAI API 标准的 API 的, 所以为了可以拉取模型请注册 huggingface 并生成一个 Access Token 配置在 shell 环境变量中:
1 | export HF_TOKEN=hf_xxxxxxxxxxxxxxxxx |
2.3 open-webui
按照 open-webui 的文档其依赖 python 11, 所以这里我们还是利用 uv 来进行安装
1 | # 安装 python 11, 如果本地有python 11 则不用 |
3. 运行和使用模型
3.1 拉取模型
使用 ollama 拉取模型
1
ollama pull phi4
使用 vllm 拉取模型
vllm 没有单独拉取命令, 这里使用 serve 命令
1
2
3
4# 激活虚拟环境(基于2.2的工作目录)
source .venv/bin/activate
# 拉取和serve大模型
vllm serve Qwen/Qwen2.5-0.5B-Instruct
3.2 启动 open-webui
启动 open-webui 很简单只需一行命令:
1 | unset DATABASE_URL OPENAI_API_KEY && open-webui serve |
之所以 unset 两个环境变量, 这两个环境变量本地 shell 都配置了, 前者配置后影响 open-webui 的数据访问存储, 后者则会在 open-webui 中加载 OpenAI 的所有模型, 这里去掉OPENAI_API_KEY open-webui 就不会自动获取 OpenAI 的所有模型了; 当然 open-webui 会自动插件 ollama 的服务端口也会获取 ollama 当前下载的模型然后在 open-webui 中显示.
Note
首次进入 open-webui 的时候需要注册一个管理账号, 请记住这个账号名和密码方便以后登录.
3.3 对话
进入 open-webui 即可以进行选择一个模型进行对话, 例如选择 phi4:lastet, 提问: 9.11 和 9.8 哪个大

上面模型回答说 9.11 大于 9.8, 这是不对了, 那么说明 phi4:latest 这个模型数学逻辑推理可能不行, 那么你可以利用 ollama 拉取一些其他模型, 选择一个性能和质量都符合自己的模型即可. 在本文所用的计算机上, 大于 14B 的模型运行吃力, 例如 deepseek-r1:32b, 所以不要一味追求尺寸大的模型, 要综合计算机配置选择模型. 经过测试推荐模型以下模型:
- deepseek-r1:32b
- qwen2.5-coder:14b
- deepseek-v2:latest
- deepseek-r1:14b
- phi4:latest
- qwen2.5:14b
4. 高级用法
4.1 启用联网搜索
在 open-webui 的设置有可以配置联网搜索, 访问 http://localhost:8080/admin/settings 然后选择联网搜索, 开启联网搜索并选择 duckduckgo 并点击保存, 之后就可以在聊天输入窗口开启联网.
Note
duckduckgo 最简单的联网搜索引擎, 其他的联网引擎都需要注册和生成 API
4.2 加载 vllm 模型
在之前 3.1 的章节 vllm serve 了一个模型, serve 之后会在本地 8080 端口提供兼容 OpenAI API 的接口, 将者这个服务地址配置在 open-webui, 就可以通过 open-webui 和 vllm serve 的模型进行对话了. 操作步骤如下:
点击进入 外部链接 设置页面
添加一个
OpenAI API连接密钥: none
启用并保存
经过上面的步骤后, open-webui 会读取这个模型, 在聊天窗口就可以切换为该模型进行对话了.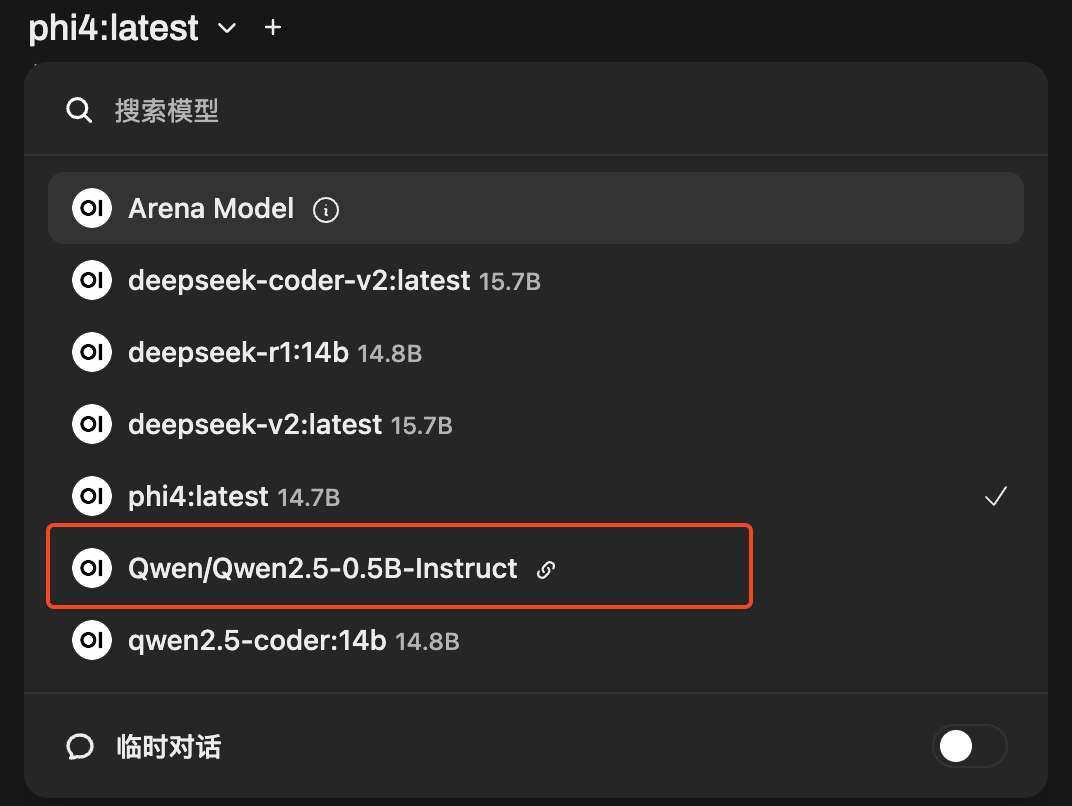
Tip
从 open-webui 外部链接的控制台可以看到其支持添加兼容 OpenAI API 的外部模型 和 Ollama API 的模型, 所以你基本可以添加任何本地或者远程模型服务.
4.3 AI 编程助手
因为本地模型服务, 所以这些模型服务也可以用在 AI 编程助手上, 这里选择的 IDE 是 VSCode, 编程助手扩展是: Continue. Continue 支持商用的大模型服务也支持 Ollama, 所以配置 Continue 让其使用本地模型服务即可以使用本地模型来编程, 配置比较简单, 这里提供一下个人配置作为参考, 如果需要了解更多 Continue 的配置和使用可以查看其官方文档: https://docs.continue.dev
1 | { |
Note
本地资源毕竟有限不要一味使用大参数模型, 在自动完成配置中qwen2.5-coder:7b-base 是官方推荐的本地质量和性能平衡中较好的选择, 如果计算机性能稍差也可以选择qwen2.5-coder:1.5b-base
5. 总结
本文通过 ollama 提供本地模型运行引擎, 搭配 open-webui 可以实现和本地模型进行交互; 另外也介绍了 vllam 如何 serve 一个模型, 不管是 ollama 和 vllam 都是运行模型并对外暴露标准的 OpenAI API 接口来调用.
本地使用大模型数据安全就不是问题了, 可以让模型分析整个代码仓库(Continue 功能), 提高工作效率.
虽然目前本地运行模型都是好一些小尺寸模型, 但是小尺寸模型是一种趋势, 例如微软的 phi 模型, 以后端侧的模型的应用和部署更是一个趋势, 建议大家积极尝试和学习.
如果觉得本文提供的本地运行大模型方式还是太复杂, 社区也有一些桌面应用程序既有 UI 界面又可以下载和运行模型, 且运行的模型都可以暴露为 OpenAI API 兼容型 API: