0. 介绍
本文是前两篇机器学习文章的延续, 前两篇分片是:
- 机器学习–Sagemaker 上手练习: 介绍了使用 AWS Sagemaker 进行机器学习, 并介绍如何生成一个模型
- 机器学习–数据整理: 如何进行数据整理
本文主要关注点在于模型的部署, 本文将弱化如何产生模型的过程, 因为之前的文章已经介绍过, 但是本文还是通过代码介绍了一下 AutoMLJob, 这是 SageMaker 的一个特性, 其可以自动进行很多步骤比如数据分析模型质量分析等任务, 最后选择一个最佳的算法生成模型, 本文以 AutoMLJob 生成的结果为例来介绍如何部署模型, 不过 AutoMLJob 不是必须, 您可以可以使用 Sagemaker 其中的其他方式构建模型, 最后主要有镜像和模型文件两个资源即可.
1. 部署基本知识
训练机器学习模型后,您可以使用 Amazon SageMaker 部署它来获取预测。Amazon SageMaker 支持以下内容 部署模型的方法,具体取决于您的用例:
- 对于一次进行一个预测的持久性实时终端节点,请使用 SageMaker 实时托管服务。请参阅实时推理。
- 在流量高峰之间具有空闲期的工作负载,并且可以容忍寒冷 开始时,使用 Serverless Inference。请参阅使用 Amazon SageMaker Serverless Inference 部署模型。
- 具有高达 1GB 的大负载大小、较长的处理时间和近乎实时的延迟要求的请求, 使用 Amazon SageMaker 异步推理。请参阅异步推理。
- 要获取整个数据集的预测,请使用 SageMaker 批量转换
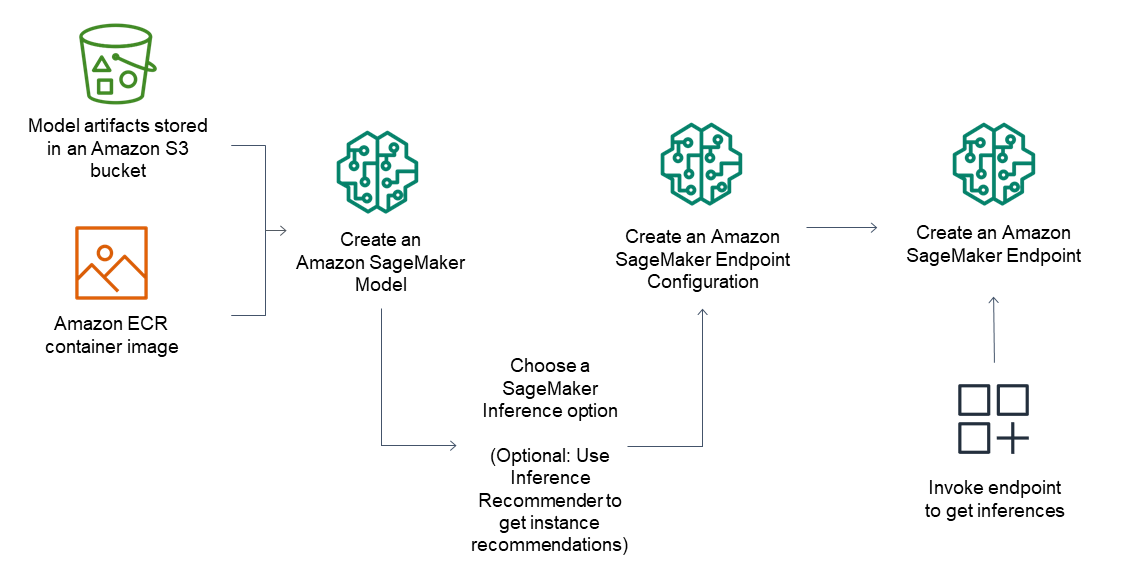
2. 模型部署步骤
对于推理端点,常规工作流包括以下内容:
- 通过指向存储在 Amazon S3 中的模型构件和容器镜像,在 SageMaker Inference 中创建模型。
- 选择一个推理选项。有关更多信息,请参阅推理选项。
- 通过选择实例类型和数量来创建 SageMaker 推理终端节点配置 您需要的实例位于终端节点后面。您可以使用 Amazon SageMaker Inference Recommender 来 获取有关实例类型的建议。对于 Serverless Inference,您只需提供 根据您的模型大小,您需要的内存配置。
- 创建 SageMaker 推理终端节点。
- 调用您的终端节点以接收推理作为响应。
3. 推理选项
SageMaker 提供了多个推理选项,以便您可以选择最适合您的工作负载的选项:
实时推理:实时 推理非常适合具有低延迟或 高吞吐量要求。使用实时推理实现持久且完全 可以处理持续流量的托管端点 (REST API),由 您选择的实例类型。实时推理可支持高达 6 MB 的有效负载大小 处理时间为 60 秒。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46import pandas as pd
import json
# Load the dataset
df = pd.read_csv('data/real-time-payload.csv')
# Check for hidden characters or extra spaces in 'unit_sales' column
df['unit_sales'] = df['unit_sales'].apply(lambda x: str(x).strip() if pd.notnull(x) else x)
# Convert 'unit_sales' column to numeric, forcing errors to NaN
df['unit_sales'] = pd.to_numeric(df['unit_sales'], errors='coerce')
# Replace null values with 0
df['unit_sales'].fillna(0, inplace=True)
# Verify there are no missing values left
missing_values = df['unit_sales'].isnull().sum()
print(f'Total missing values in unit_sales after filling: {missing_values}')
# Save the cleaned dataset
df.to_csv('data/default-real-time-payload.csv', index=False)
timestamp_suffix = strftime("%Y%m%d-%H%M%S", gmtime())
auto_ml_job_name = "ts-20240807-094452"
print("AutoMLJobName: " + auto_ml_job_name)
# Create auto ml job
sm.create_auto_ml_job(
AutoMLJobName=auto_ml_job_name,
InputDataConfig=[
{
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": 's3://{}/{}/data/'.format(bucket, prefix),
}
},
"TargetAttributeName": 'unit_sales',
}
],
OutputDataConfig={"S3OutputPath": 's3://{}/{}/train_output'.format(bucket, prefix)},
ProblemType='Regression',
AutoMLJobObjective={"MetricName": 'RMSE'},
AutoMLJobConfig={"CompletionCriteria": {"MaxCandidates": 3}},
RoleArn=role,
)等待 AutoMLJob 处理完成然后部署模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39# 从AutoML中获取模型文件和容器信息
best_candidate = sm.describe_auto_ml_job(AutoMLJobName=auto_ml_job_name)['BestCandidate']
best_candidate_containers = best_candidate['InferenceContainers']
best_candidate_name = best_candidate['CandidateName']
# 创建模型
reponse = sm.create_model(
ModelName = best_candidate_name,
ExecutionRoleArn = role,
Containers = best_candidate_containers
)
# 模型端点配置信息
endpoint_config_name = f"epc-{best_candidate_name}"
endpoint_name = f"ep-{best_candidate_name}"
production_variants = [
{
"InstanceType": "ml.t2.large",
"InitialInstanceCount": 1,
"ModelName": best_candidate_name,
"VariantName": "AllTraffic",
"ManagedInstanceScaling": {
"Status": "ENABLED",
"MinInstanceCount": 1,
"MaxInstanceCount": 2,
}
# "VolumeSizeInGB": 100
}
]
# 创建模型端点配置
epc_response = sm.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=production_variants
)
# 创建模型端点
sm.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name)Note
t2 等突发性能的规格不支持自动伸缩, 经济客观的规格是: ml.m5.large
Important
以上脚本均是 jupyter 脚本, 主要是说明整个部署流程, 核心是先创建 AutoMLJob, 个人觉得 AutoMLJob 是数据科学家和 DevOps 工程师的分界点, 数据科学家通过 AutoMLJob 训练模型, 而 DevOps 依赖其进行部署.
无服务器推理:当您有无服务器推理时,无服务器推理是理想的选择 间歇性或不可预测的流量模式。SageMaker 管理所有 底层基础设施,因此无需管理实例或扩展 政策。您只需为使用的内容付费,而不为空闲时间付费。它可以支持高达 4 MB 的有效负载大小 处理时间长达 60 秒。
Caution
中国区不支持
批量转换:批量转换适用于大量数据可用时的离线处理 预先,您不需要持久性终结点。您也可以使用批处理 用于预处理数据集的 transform。它可以支持 GB 大小的大型数据集 和处理时间(以天为单位)。
异步推理:异步推理是 当您想要对请求进行排队并具有较长的大型有效负载时,这是理想的选择 处理时间。异步推理可以支持高达 1 GB 的有效负载和长时间的处理 时间长达一小时。当有时,您还可以将终结点缩减为 0 无需处理任何请求。
Note
虽然异步方式不要求队列, 但是从业务逻辑上分析, 始终需要一个事件(时间)知道处理结果, 特别是处理错误时, 所以建议实际应用时增加队列.
4. 部署模型
通过 CDK 进行部署, 前提是已经通过 AutoMLJob 训练结束, 相关代码如下:
1 | import { |
Important
在 appscaling.CfnScalingPolicy 的时候会出创建自定义策略来实现伸缩, 但是 endpoint 默认还有一个内置策略名字是: SageMakerEndpointInvocationScalingPolicy, 如果将policyName名称修改为内置策略名称则可以修改内置策略来实现伸缩.
5. Lambda 调用
权限设置
以
serverless框架为例, 在 serverless.ts 的 iam.role 中配置如下权限语句1
2
3
4
5
6// SageMaker
{
Effect: 'Allow',
Action: ['sagemaker:*'],
Resource: ['arn:aws-cn:sagemaker:${self:provider.region}:*:endpoint/*'],
},调用
使用
@aws-sdk/client-sagemaker-runtime客户端进行调用. 首先生成客户端1
private readonly smClient = new SageMakerRuntimeClient()
然后使用客户端进行调用和调用 S3 类似:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21async invokeSegemaker() {
const result = await this.smClient.send(
new InvokeEndpointCommand({
EndpointName: this.configService.get('demoMLModelEndpoint'),
ContentType: 'text/csv',
Body: `product_code,product_category,product_subcategory,location_code,scaled_price,promotion_email,promotion_homepage,timestamp
1062,Beverages,Fruit Juice Mango,110,0.878183107,0,0,2018-01-01
1062,Beverages,Fruit Juice Mango,110,1.0,0,0,2018-01-08
1062,Beverages,Fruit Juice Mango,110,1.005453752,0,0,2018-01-15
1062,Beverages,Fruit Juice Mango,110,1.0,0,0,2018-01-22
1062,Beverages,Fruit Juice Mango,110,0.887865924,0,0,2018-01-29
1062,Beverages,Fruit Juice Mango,110,0.872730247,0,0,2018-02-05
1062,Beverages,Fruit Juice Mango,110,0.888925241,0,0,2018-02-12`,
})
)
return {
body: Buffer.from(result.Body).toString(),
httpStatusCode: result.$metadata.httpStatusCode,
contentType: result.ContentType,
}
}返回结果如下:
1
2
3
4
5
6
7
8
9
10{
"code": 0,
"message": null,
"error": null,
"data": {
"body": "396.341796875\n214.32861328125\n204.45921325683594\n208.49118041992188\n205.5048370361328\n214.2066650390625\n214.7940673828125\n214.4359893798828\n",
"httpStatusCode": 200,
"contentType": "text/csv; charset=utf-8"
}
}Important
注意返回类型是 text/csv, 可以通过换行符
\n来分割数据, 每一行数据则是调用时所传每一行参数的预测结果