0. 介绍
本文介绍在机器学习之前如何进行数据处理, 数据处理是机器学习的必经之路, 而且数据的质量也非常影响最后模型的效果. 本文介绍两种工具进行数据整理, 分别是 AWS 的 Data Wrangler 和 VS Code 的 Data Wrangler Extension, 前者在第一节, 后者在第二节.
AWS Data Wrangler 集成在 SageMaker 产品的 Studio 中, 使用方便, 有很多自动化的功能帮助我们进行数据整理和查看数据质量报告, 但是开发者背景的工程师可能不太习惯这种方式, 所以本文又介绍 VS Code 的 Data Wrangler Extension, 这个扩展工具也很好用, 但是没有数据质量分析报告, 所以要看报告的话可以按照 AWS 相关文档中提示的, 可以结合altair进行数据质量分析.
本文中包含很多图片, 图床时 Github Gist, 所以需要科学上网.
1. 使用 Amazon Data Wrangler 准备机器学习 SageMaker 数据
Amazon SageMaker Data Wrangler(Data Wrangler)是 Amazon SageMaker Studio Classic 的一项功能,它提供了导入、准备、转换、特征化和分析数据的 end-to-end 解决方案。您可以将 Data Wrangler 数据准备流集成到机器学习 (ML) 工作流中,以简化和精简数据预处理和特征工程,只需少量甚至无需编码。您还可以添加自己的 Python 脚本和转换,以自定义工作流。
Data Wrangler 可提供以下核心功能,帮助您分析和准备用于机器学习应用程序的数据。
导入
连接亚马逊简单存储服务 (Amazon S3)、(Athena)、亚马逊 Redshift、Snow Amazon Athena flake 和 Databricks 并从中导入数据。
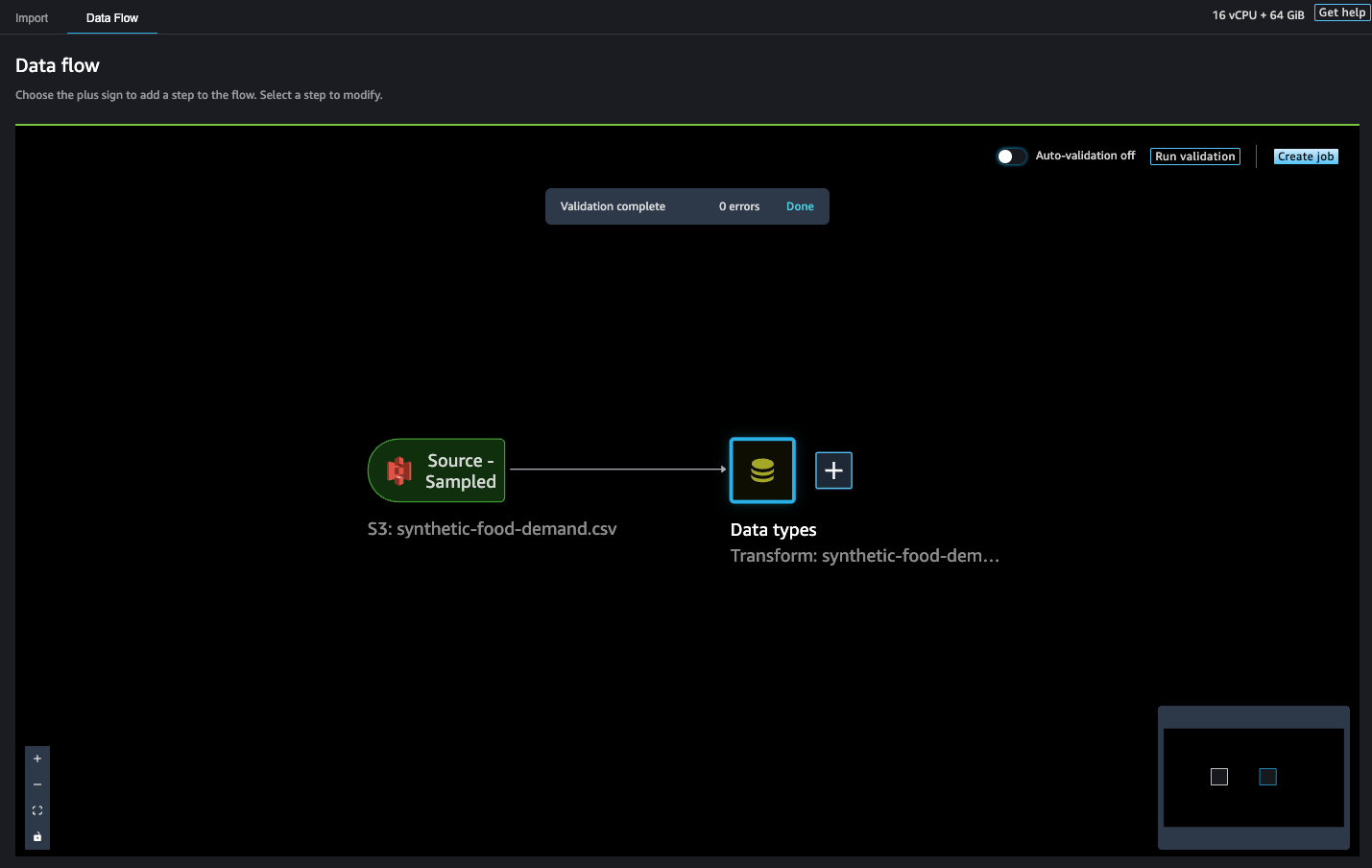
数据流
创建数据流以定义一系列机器学习数据准备步骤。您可以使用流合并来自不同数据源的数据集,确定要应用于数据集的转换数量和类型,并定义可集成到机器学习管线中的数据准备工作流。
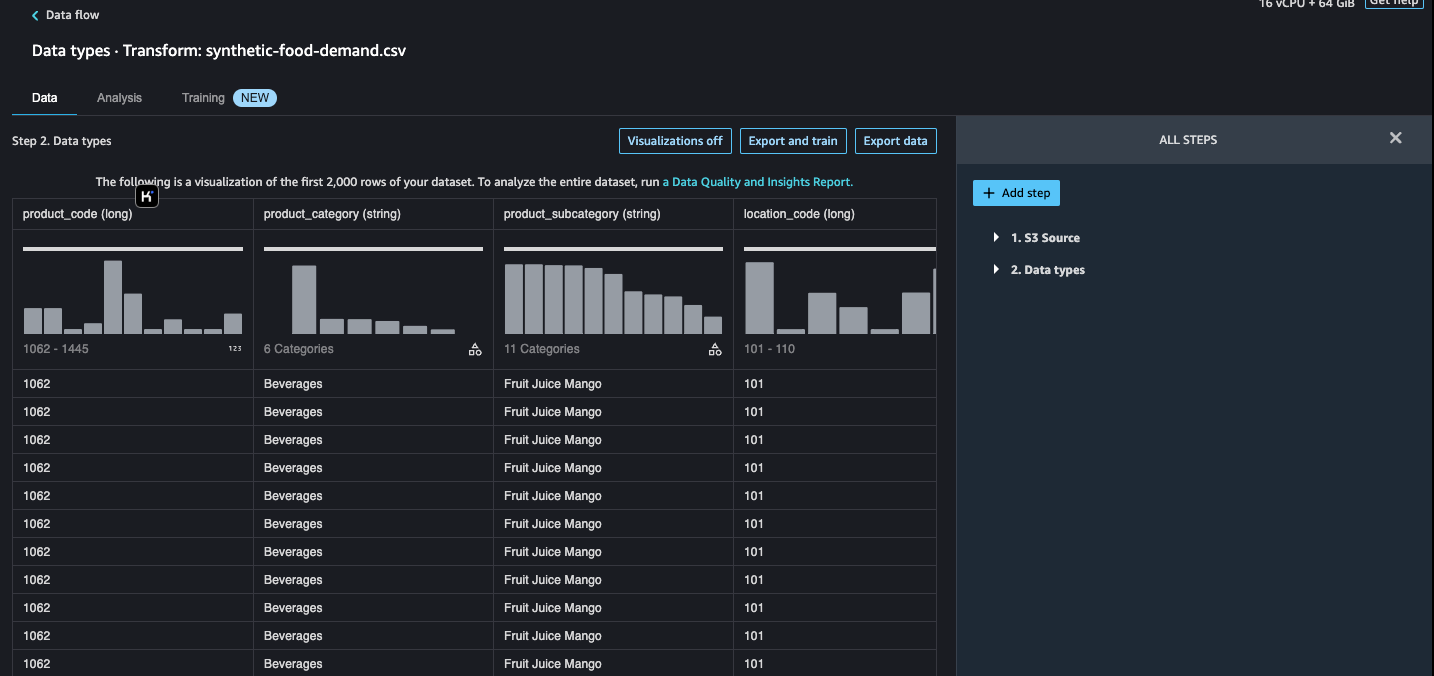
转换
使用标准转换(如字符串、矢量和数字数据格式化工具)清理和转换数据集。使用转换(如文本和日期/时间嵌入以及分类编码)特征化数据。
生成数据见解
使用 Data Wrangler 数据见解和质量报告,自动验证数据质量并检测数据中的异常。
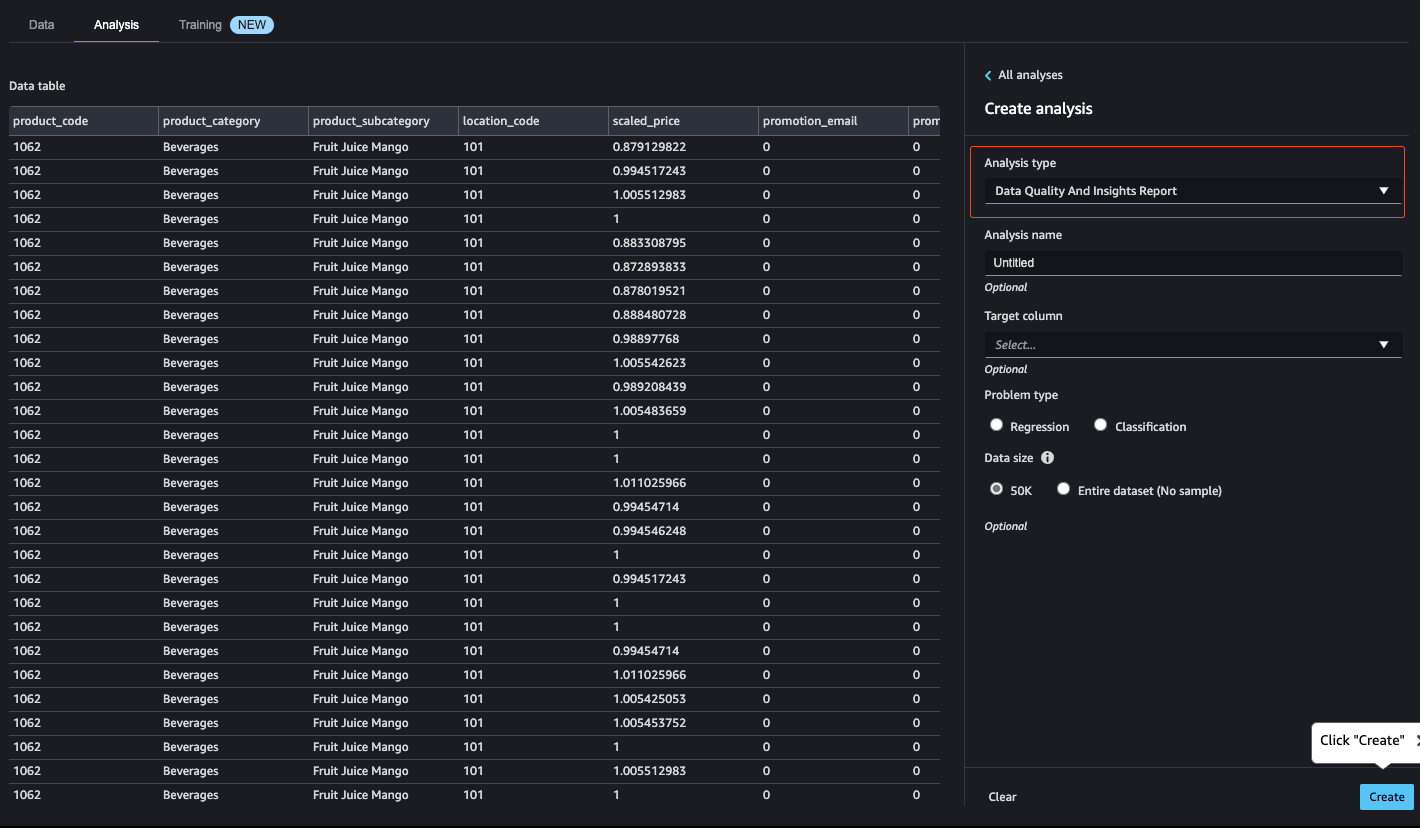
分析
在流中的任意点分析数据集中的特征。Data Wrangler 包括内置的数据可视化工具,如散点图和直方图,以及目标泄漏分析和快速建模等数据分析工具,以了解特征相关性。
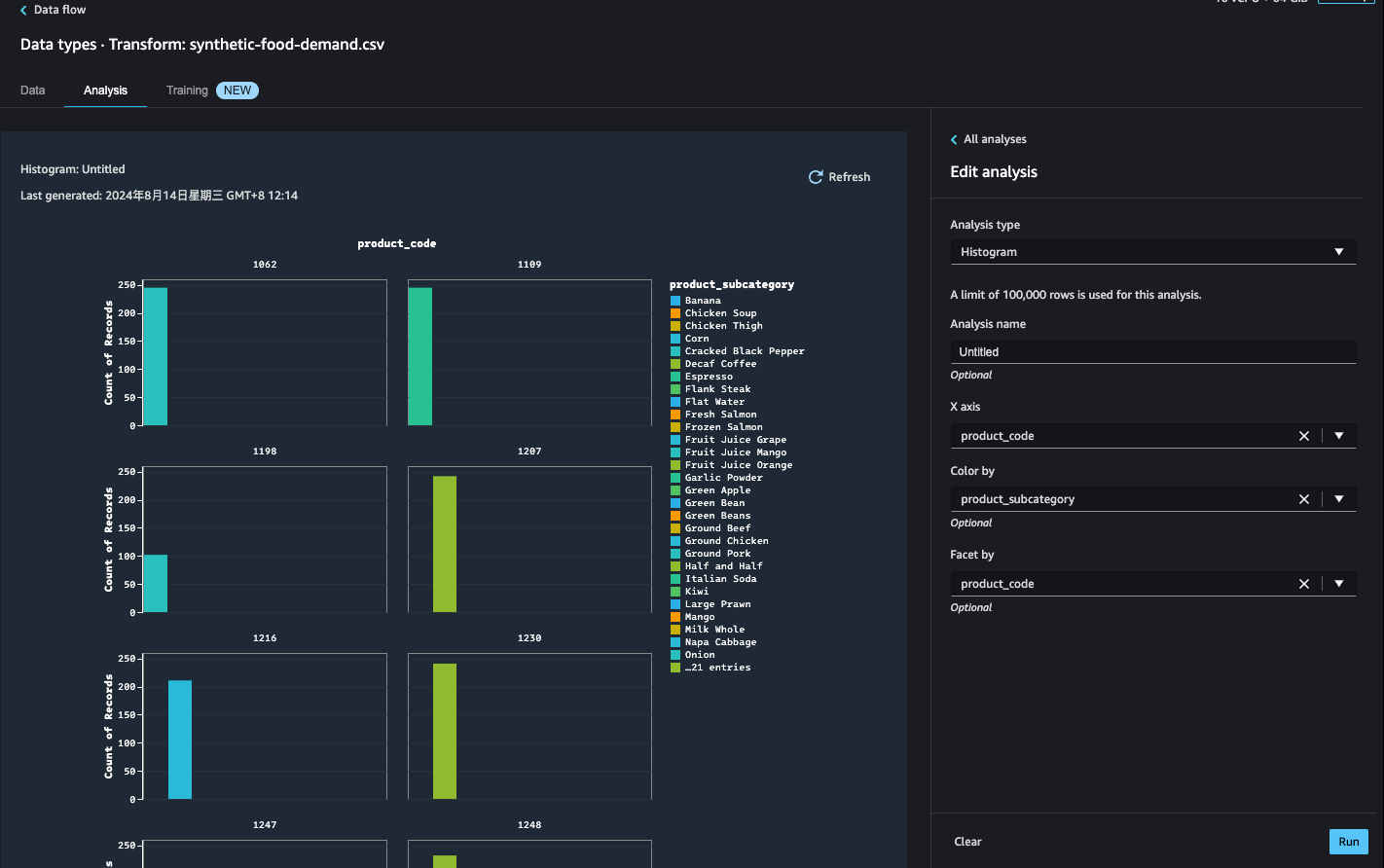

导出
将数据准备工作流导出至其他位置。以下是一些示例位置:
- Amazon Simple Storage Service (Amazon S3)桶
- Amazon SageMaker 模型构建管道 — 使用 SageMaker 管道自动部署模型。您可以将转换后的数据直接导出至管线。
- Amazon F SageMaker eature Store — 将功能及其数据存储在中央存储中。
- Python 脚本 – 将数据及其转换存储在 Python 脚本中,用于您的自定义工作流
2. 总结和实践
Data Wrangle 集成在 Studio 中, 对开发背景的数据科学家来说不太友好, 因为开发者背景工程师和喜欢使用自己的工具尽量在本地调试
awesome-data-wrangling: A curated list of data wrangling resources with a bias towards command line tools without steep learning curves.
利用Data Wrangler Extension for Visual Studio Code进行数据质量分析
- 查看模式
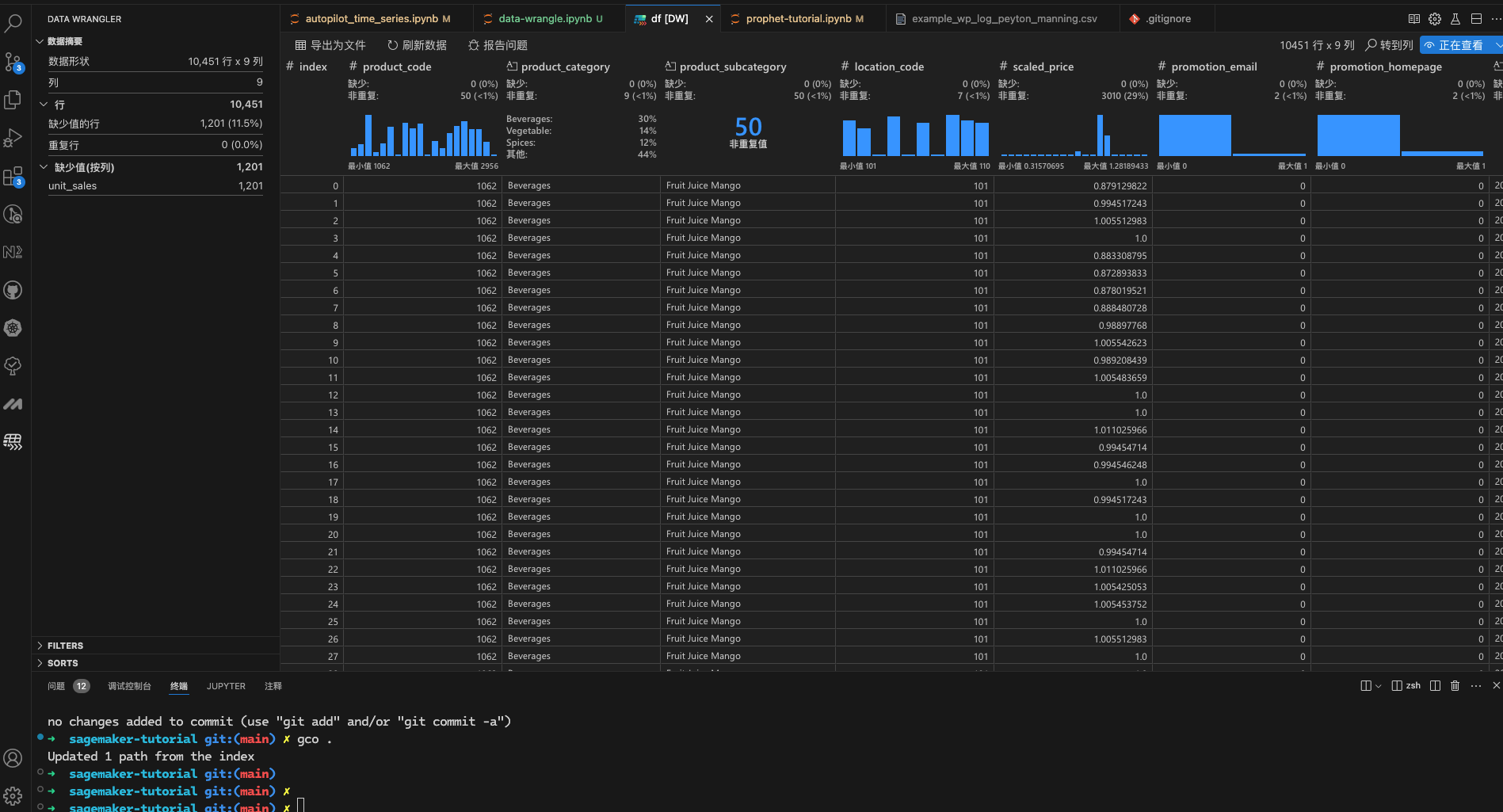
编辑模式
选择列填充默认值
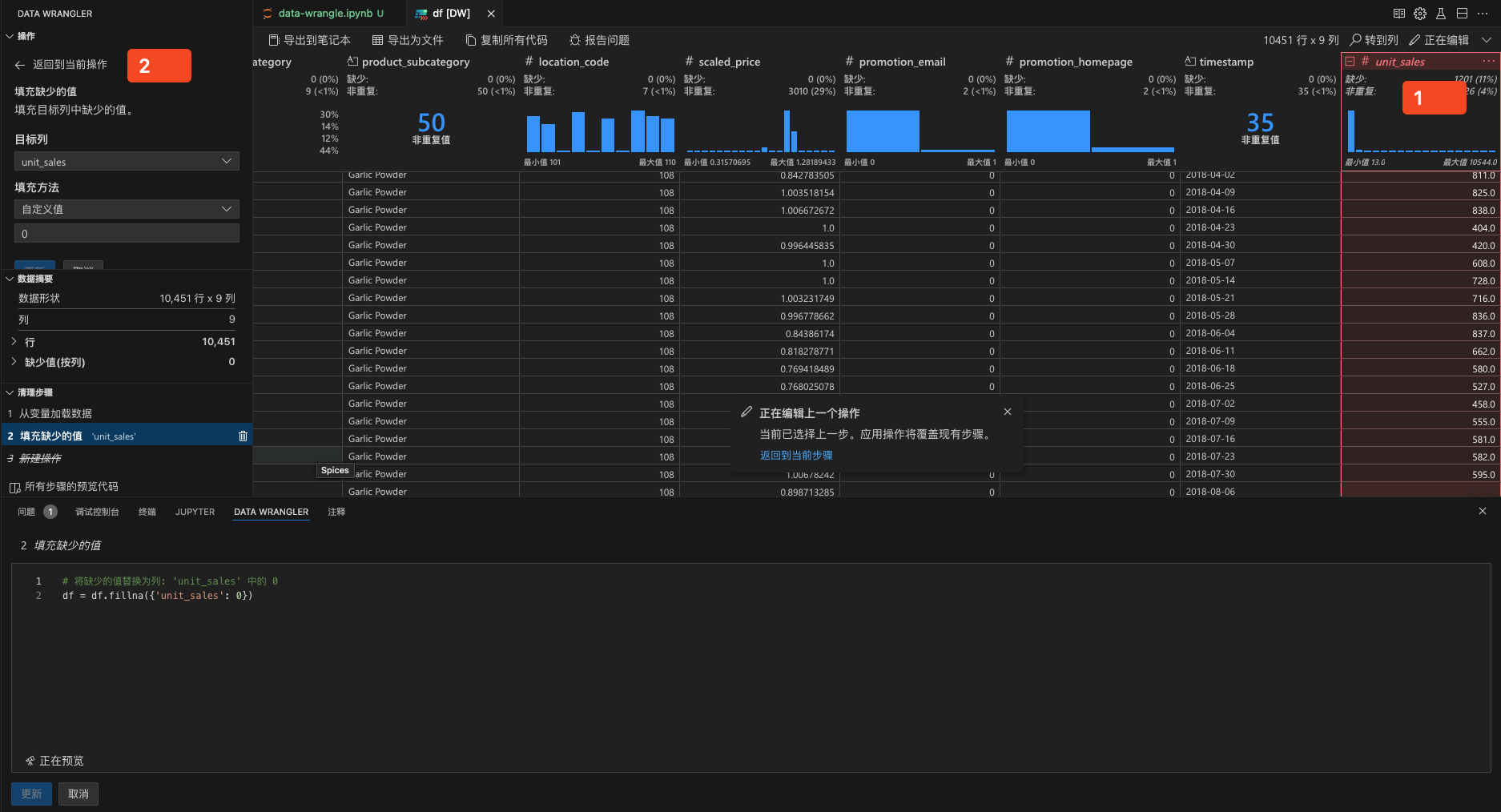
多个步骤进行数据处理并导出
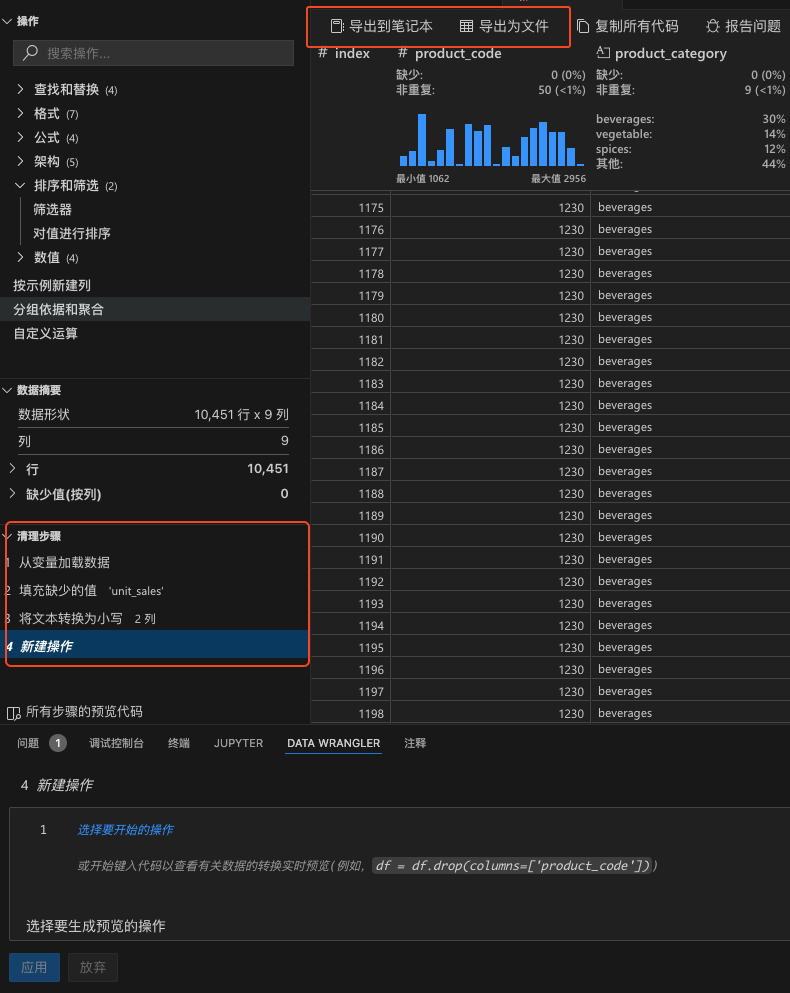
导出到笔记
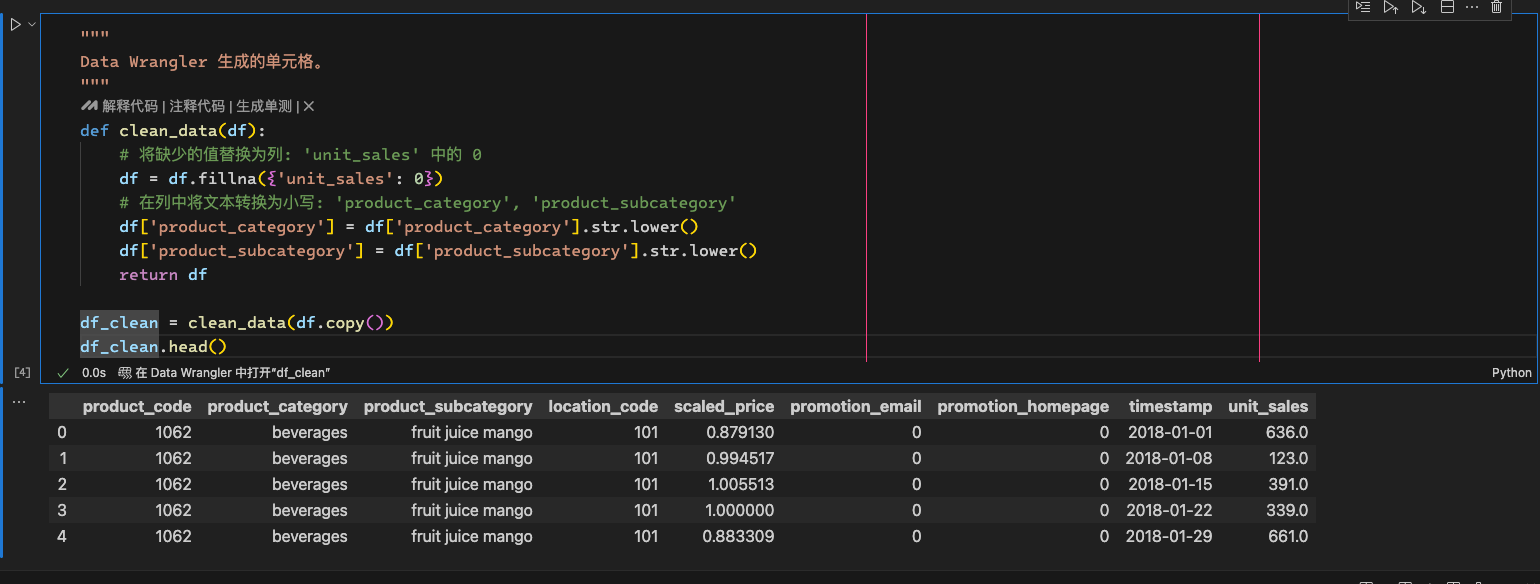
结合altair进行数据质量观察
1
2
3
4
5import altair as alt
alt.data_transformers.disable_max_rows()
# sampled_data = df_clean.sample(n=5000, random_state=1)
# sampled_data['timestamp'] = pd.to_datetime(sampled_data['timestamp'])1
2
3
4
5
6
7line_chart = alt.Chart(df_clean).mark_line().encode(
x='timestamp:T',
y='unit_sales:Q'
).properties(
title='Unit Sales Over Time'
)
line_chart.show()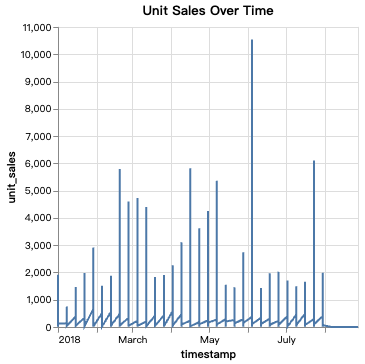
1
2
3
4
5
6
7
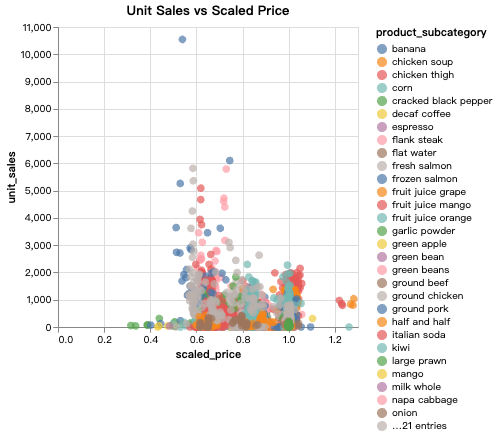
8scatter_plot = alt.Chart(df_clean).mark_circle(size=60).encode(
x='scaled_price:Q',
y='unit_sales:Q',
color='product_subcategory:N'
).properties(
title='Unit Sales vs Scaled Price'
)
scatter_plot.show()